We cannot confidently call ourselves Linux file management experts without the mastery of text processing. Three known command-line tools (grep, sed, and awk) have built their reputation as Linux text processors. They come pre-installed on all major Linux operating system distributions hence no need to query their existence via a Linux package manager.
Despite grep, sed, and awk commands being uniquely attributed in their text processing functionalities, some simple scenarios force their functionalities to slightly overlap.
For instance, all these three commands can comfortably query the possibility of a file pattern match and forward the query results to standard output.
This article aims to clearly identify the distinguishing factor among these three text processing commands.
Additionally, this article aims to conclude that:
- If you are looking for simple text matching and printing solutions, consult the grep command.
- If you are looking for additional text transformation solutions (e.g substitution) on top of matching and printing texts, consult the sed command.
- If you are looking for a multitude of text processing features from a powerful scripting language, consult the awk command.
Problem Statement
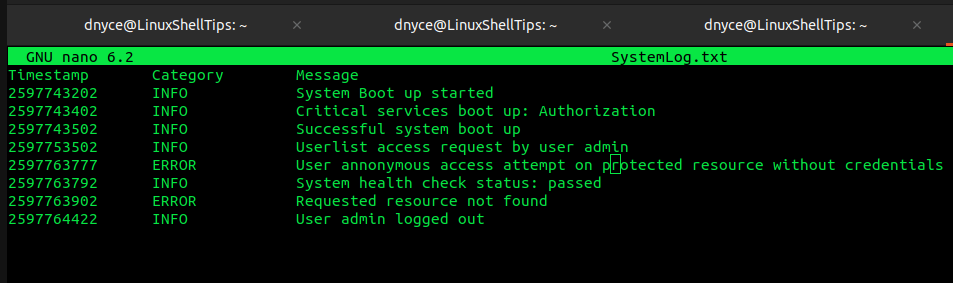
To make this tutorial more informative and relatable, let us define a sample text file that we will be referencing. Consider the following created text file called SystemLog.txt which accounts for various system activities based on a specified timestamp.
The grep Command in Linux
By definition, the grep command matches and prints text based on a regex pattern. It is a quick solution for querying the existence of a particular line on a targeted file.
Its usage syntax is as follows:
$ grep [OPTION...] PATTERNS [FILE...]
In the above syntax, PATTERNS denotes the regex pattern defined by a user which the grep command will reference.
Searching for Regex Pattern Match on User-Defined Lines
In reference to the system log file we earlier created, let us assume we want to highlight all the ERROR events in the file, our grep command will look like the following:
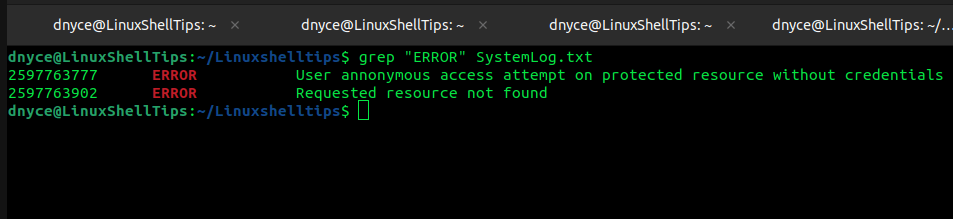
$ grep "ERROR" SystemLog.txt
The grep command will search for any occurrence of the line ERROR in the SystemLog.txt file before printing the results to the standard output.
Inverting the Line Match
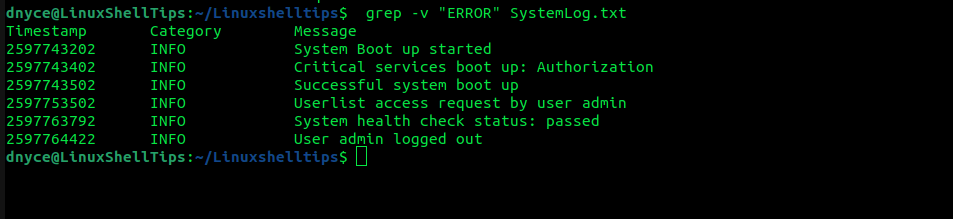
Suppose we want all lines in the file to be printed except the one specified on the grep command. In this case, we will use the -v option.
$ grep -v "ERROR" SystemLog.txt
Printing Preceding/Succeeding Lines
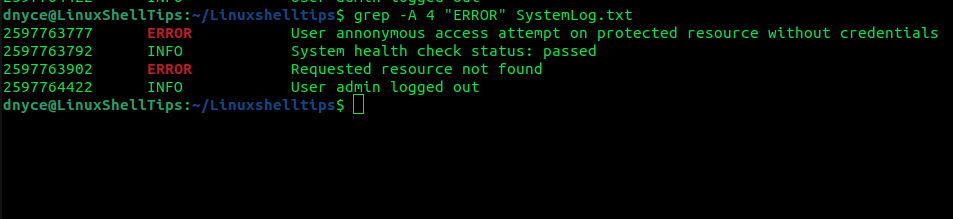
To print 4 lines after the ERROR line match:
$ grep -A 4 "ERROR" SystemLog.txt
To print 4 lines before the ERROR line match:
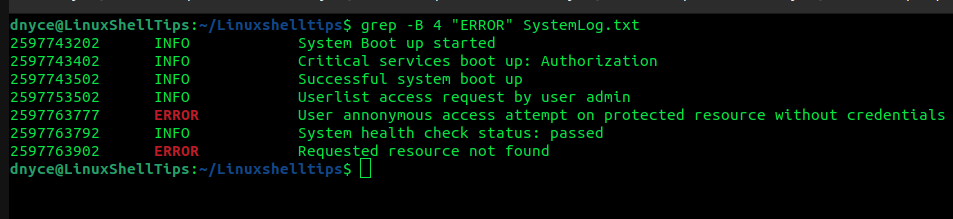
$ grep -B 4 "ERROR" SystemLog.txt
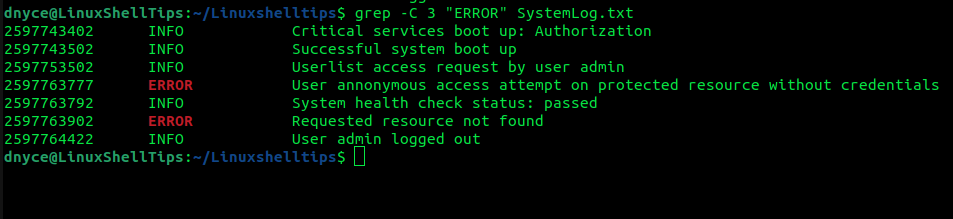
To print 3 lines before and after the ERROR line match:
$ grep -C 3 "ERROR" SystemLog.txt
The sed Command in Linux
The sed command has an advantage over grep due to its additional text processing features.
Its reference syntax is as follows:
$ sed [OPTION]... {script-only-if-no-other-script} [input-file]...
Using sed as grep
The sed equivalent of the grep command for searching and printing file entries associated with the line ERROR is as follows:
$ sed -n '/ERROR/ p' SystemLog.txt
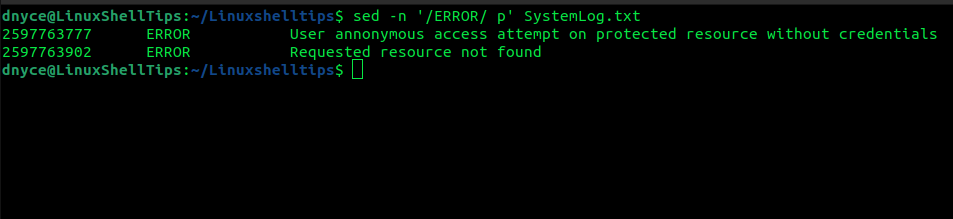
The -n option prevents sed from printing each scanned line.
Substituting Matched String with Replacement
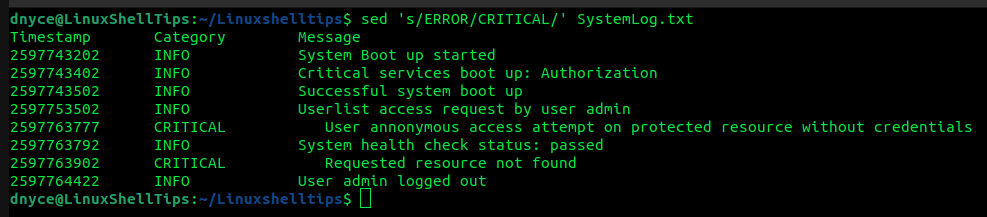
Supposing we wish to substitute the line ERROR with the line GLITCH in our text file, the sed command implementation will look like the following:
$ sed 's/ERROR/CRITICAL/' SystemLog.txt
Modifying Files in Place
Using the flag -i together with a user-defined suffix enables sed to create a backup copy of the input file before applying persistent user-intended operations.
For instance, we can rename the line CRITICAL back to ERROR only after creating a backup copy of the original file state.
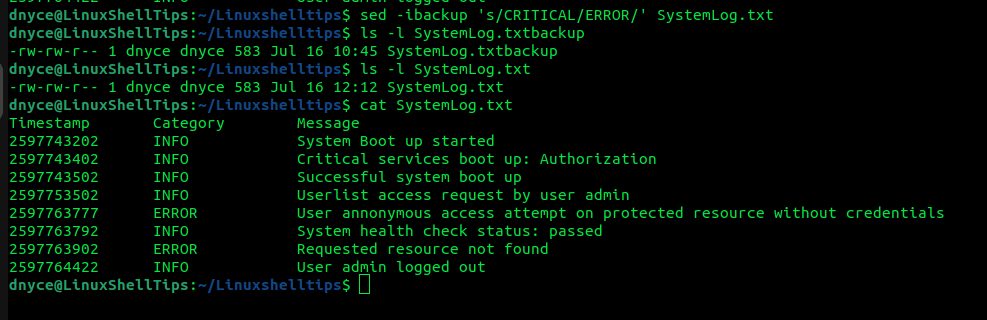
$ sed -ibackup 's/CRITICAL/ERROR/' SystemLog.txt
The original file will be renamed to SystemLog.txt backup.
$ ls -l SystemLog.txtbackup
We can also confirm via the cat command that the file changes took place:
$ cat SystemLog.txt
Restricting sed to Specific Line Number
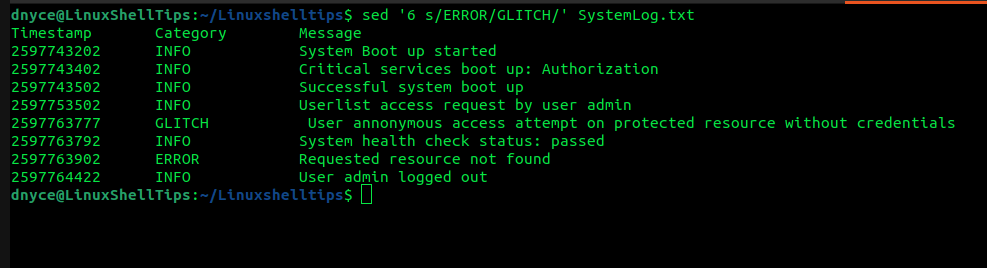
To restrict sed operations to line number 6 of the text file, implement:
$ sed '6 s/ERROR/GLITCH/' SystemLog.txt
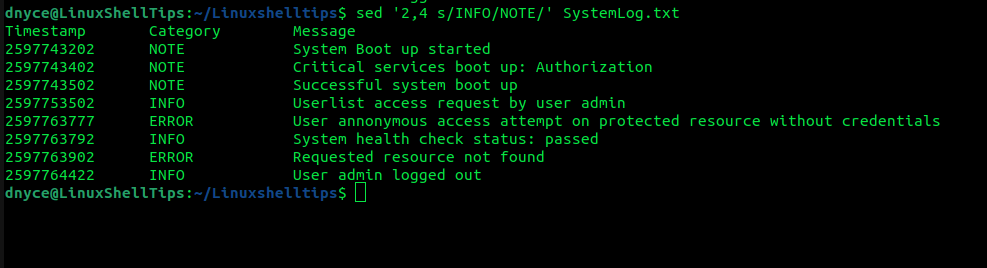
To specify an operation ranging from like 2 to 4, implement:
$ sed '2,4 s/INFO/NOTE/' SystemLog.txt
To print pattern matches from a specific line onward, e.g line 5, implement:
$ sed -n '5,/INFO/ p' SystemLog.txt

The awk Command in Linux
The awk command can be used to perform time, arithmetic, and string manipulation because of its multitude of built-in operations. Also, users are allowed to define their customizable functions.
Its basic syntax is as follows:
$ awk [options] script file
Replacing grep with awk
The awk equivalent of the grep command to search a line in a file is as follows:
$ awk '/ERROR/{print $0}' SystemLog.txt

Substituting a Matching String
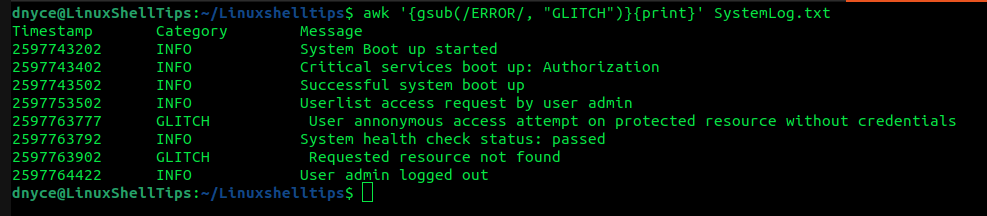
The awk command uses gsub (a built-in method) for line substitution operations.
$ awk '{gsub(/ERROR/, "GLITCH")}{print}' SystemLog.txt
Adding Headers and Footers
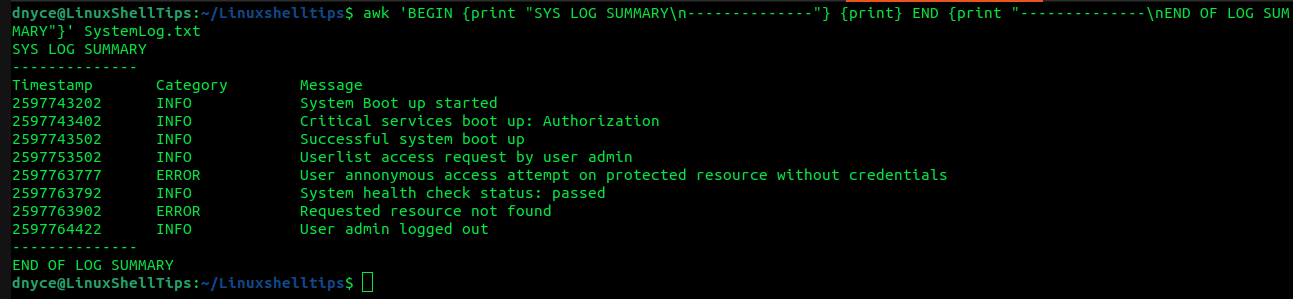
We can add headers and footers to input files using awk’s BEGIN and END blocks as demonstrated below:
$ awk 'BEGIN {print "SYS LOG SUMMARY\n--------------"} {print} END {print "--------------\nEND OF LOG SUMMARY"}' SystemLog.txt
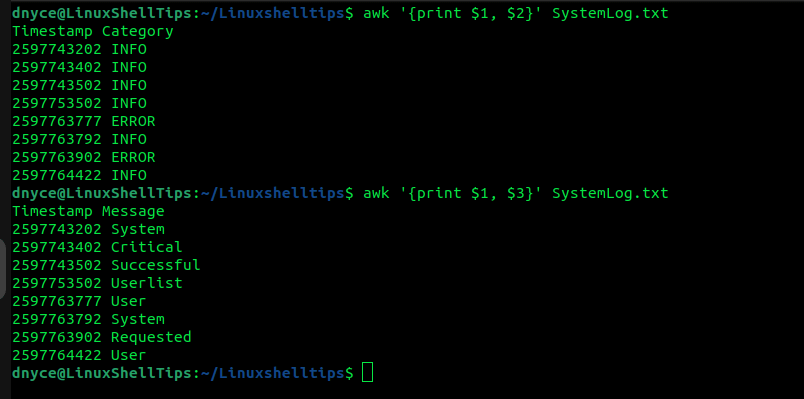
Column Manipulation
For documents like CSV files with row and column structures, we can be specific in only printing the 1st and 2nd columns or 1st and 3rd columns as per the user’s choosing.
$ awk '{print $1, $2}' SystemLog.txt
Custom Field Separator
The default implementation of the awk command acknowledges white spaces as delimiters. If the text being processed uses characters like commas or semicolons as delimiters, you can specify them in the following manner:
$ awk -F "," '{print $1, $2}' SystemLog.txt
or
$ awk -F ";" '{print $1, $2}' SystemLog.txt
Arithmetic Operations
We could count the occurrence of the line INFO in the text file in the following manner.
$ awk '{count[$2]++} END {print count["INFO"]}' SystemLog.txt
Numeric Comparison
The awk script comfortably interprets values as a number and not just as a string. For instance, we could retrieve file entries with timestamps older than 2597763777 in the following manner:
$ awk '{ if ($1 > 2597763777 ) {print $0} }' SystemLog.txt

We can now fully differentiate the simplicities and complexities associated with grep, sed, and awk commands depending on the text processing depth we wish to achieve.
Hope you found this article guide to be informative. Feel free to leave a comment or feedback.
There is probably a typo in:
“To print 3 lines before and after the ERROR line match:
Shouldn’t be with option
-C?@Ricardo,
Yes, it’s
-Coptions, corrected in the article.